
Employing cloud services can incur a great deal of risk if not planned and designed correctly. In fact, this is really no different than the challenges that are inherit within a single on-premises data center implementation. Power outages and network issues are common examples of challenges that can put your service — and your business — at risk.
For AWS cloud service, we have seen large-scale regional outages that are documented on the AWS Post-Event Summaries page. To gain a broader look at other cloud providers and services, the danluu/post-mortems repository provides a more holistic view of the cloud in general.
It’s time for service owners relying (or planning) on a single region to think hard about the best way to design resilient cloud services. While I will utilize AWS for this article, it is solely because of my level of expertise with the platform and not because one cloud platform should be considered better than another.
A Single-Region Approach Is Doomed to Fail
A cloud-based service implementation can be designed to leverage multiple availability zones. Think of availability zones as distinct locations within a specific region, but they are isolated from other availability zones in that region. Consider the following cloud-based service running on AWS inside the Kubernetes platform:
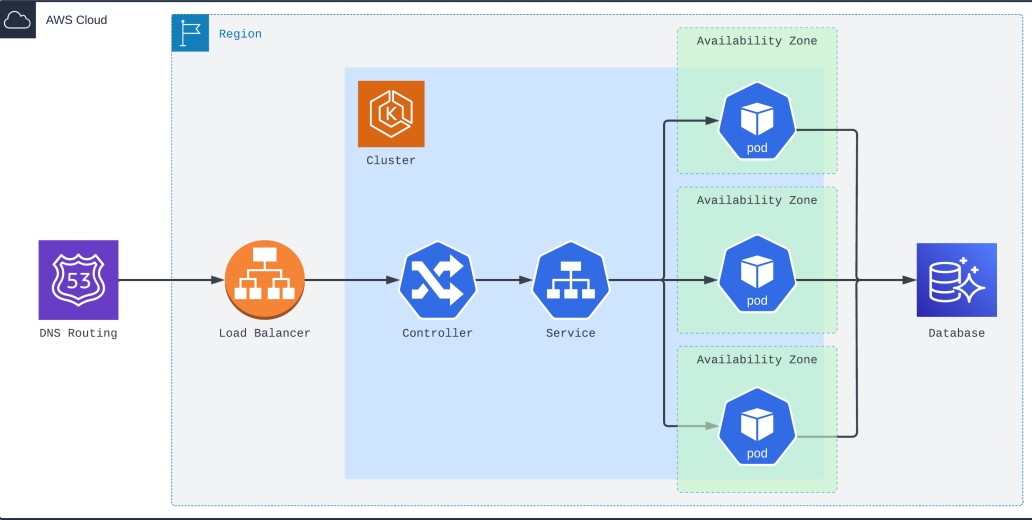
Figure 1: Cloud-based service utilizing Kubernetes with multiple availability zones
In Figure 1, inbound requests are handled by Route 53, arrive at a load balancer, and are directed to a Kubernetes cluster. The controller routes requests to the service that has three instances running, each in a different availability zone. For persistence, an Aurora Serverless database has been adopted.
While this design protects from the loss of one or two availability zones, the service is considered at risk when a region-wide outage occurs, similar to the AWS outage in the US-EAST-1 region on December 7th, 2021. A common mitigation strategy is to implement stand-by patterns that can become active when unexpected outages occur. However, these stand-by approaches can lead to bigger issues if they are not consistently participating by handling a portion of all requests.
Transitioning to More Than Two
With single-region services at risk, it’s important to understand how to best proceed. For that, we can draw upon the simple example of a trucking business. If you have a single driver who operates a single truck, your business is down when the truck or driver is unable to fulfill their duties. The immediate thought here is to add a second truck and driver. However, the better answer is to increase the fleet by two, which allows for an unexpected issue to complicate the original situation.
This is known as the “n + 2” rule, which becomes important when there are expectations set between you and your customers. For the trucking business, it might be a guaranteed delivery time. For your cloud-based service, it will likely be measured in service-level objectives (SLOs) and service-level agreements (SLAs).
It is common to set SLOs as four nines, meaning your service is operating as expected 99.99% of the time. This translates to the following error budgets, or down time, for the service:
- Month = 4 minutes and 21 seconds
- Week = 1 minute and 0.48 seconds
- Day = 8.6 seconds
If your SLAs include financial penalties, the importance of implementing the n + 2 rule becomes critical to making sure your services are available in the wake of an unexpected regional outage. Remember, that December 7, 2021 outage at AWS lasted more than eight hours.
The cloud-based service from Figure 1 can be expanded to employ a multi-region design:
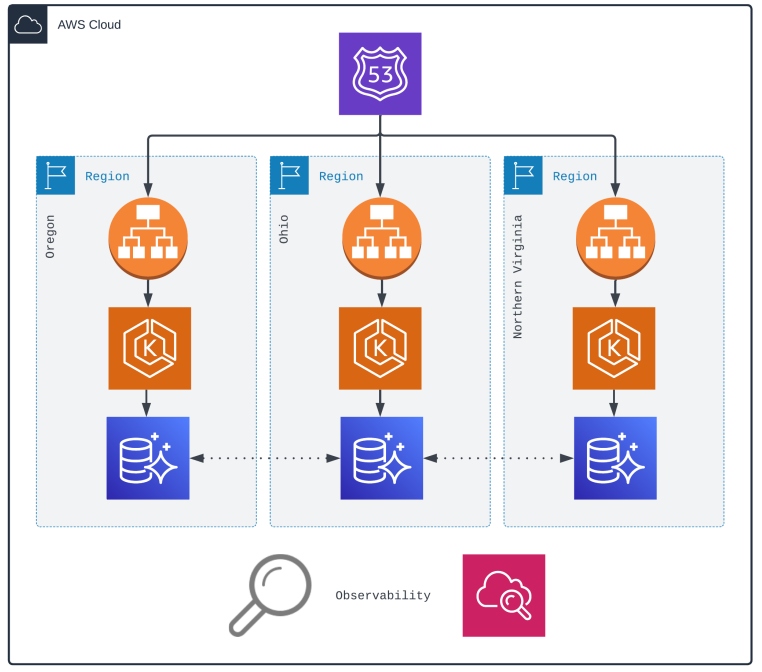
Figure 2: Multi-region cloud-based service utilizing Kubernetes and multiple availability zones
With a multi-region design, requests are handled by Route 53 but are directed to the best region to handle the request. The ambiguous term “best” is used intentionally, as the criteria could be based upon geographical proximity, least latency, or both. From there, the in-region Kubernetes cluster handles the request — still with three different availability zones.
Figure 2 also introduces the observability layer, which provides the ability to monitor cloud-based components and establish SLOs at the country and regional levels. This will be discussed in more detail shortly.
Getting Out of the Toil Game
Google Site Reliability Engineering’s Eric Harvieux defined toil as noted below:
“Toil is the kind of work that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.”
When designing services that run in multiple regions, the amount of toil that exists with a single region becomes dramatically larger. Consider the example of creating a manager-approved change request every time code is deployed into the production instance. In the single-region example, the change request might be a bit annoying, but it is something a software engineer is willing to tolerate. Now, with two additional regions, this will translate to three times the amount of change requests, all with at least one human-based approval being required.
An obtainable and desirable end-state should still include change requests, but these requests should become part of the continuous delivery (CD) lifecycle and be created automatically. Additionally, the observability layer introduced in Figure 2 should be leveraged by the CD tooling in order to monitor deployments — rolling back in the event of any unforeseen circumstances. With this approach, the need for human-based approvals is diminished, and unnecessary toil is removed from both the software engineer requesting the deployment and the approving manager.
Harnessing the Power of Observability
Observability platforms measure a system’s state by leverage metrics, logs, and traces. This means that a given service can be measured by the outputs it provides. Leading observability platforms go a step further and allow for the creation of synthetic API tests that can be used to exercise resources for a given service. Tests can include assertions that introduce expectations — like a particular GET request will respond with an expected response code and payload within a given time period. Otherwise, the test will be marked as failed.
SLOs can be attached to each synthetic test, and each test can be executed in multiple geographical locations, all monitored from the observability platform. Taking this approach allows service owners the ability to understand service performance from multiple entry points. With the multi-region model, tests can be created and performance thereby monitored at the regional and global levels separately, thus producing a high degree of certainty on the level of performance being produced in each region.
In every case, the power of observability can justify the need for manual human-based change approvals as noted above.
Bringing It All Together
From the 10,000-foot level, the multiregion service implementation from Figure 2 can be placed onto a United States map. In Figure 3, the database connectivity is mapped to demonstrate the inner-region communication, while the observability and cloud metrics data are gathered from AWS and the observability platform globally.

Figure 3: Multi-region service adoption placed near the respective AWS regions
Service owners have peace of mind that their service is fully functional in three regions by implementing the n + 2 rule. In this scenario, the implementation is prepared to survive two complete region outages. As an example, the eight-hour AWS outage referenced above would not have an impact on the service’s SLOs/ SLAs during the time when one of the three regions is unavailable.
Charting a Plan Toward Multi-Region
Implementing a multi-region footprint for your service without increasing toil is possible, but it does require planning. Some high-level action items are noted below:
- Understand your persistence layer – Understanding your persistence layer early on is key. If multiple-write regions are not a possibility, alternative approaches will be required.
- Adopt Infrastructure as Code – The ability to define your cloud infrastructure via code is critical to eliminate toil and increase the ability to adopt additional regions, or even zones.
- Use containerization – The underlying service is best when containerized. Build the container you wish to deploy during the continuous integration stage and scan for vulnerabilities within every layer of the container for added safety.
- Reduce time to deploy – Get into the habit of releasing often, as it only makes your team stronger.
- Establish SLOs and synthetics – Take the time to set SLOs for your service and write synthetic tests to constantly measure your service — across every environment.
- Automate deployments – Leverage observability during the CD stage to deploy when a merge-to-main event occurs. If a dev deploys and no alerts are emitted, move on to the next environment and continue all the way to production.
Conclusion
It’s important to understand the limitations of the platform where your services are running. Leveraging a single region offered by your cloud provider is only successful when there are zero region-wide outages. Based upon prior history, this is no longer good enough and is certain to happen again. No cloud provider is ever going to be 100% immune from a region-wide outage.
A better approach is to utilize the n + 2 rule and increase the number of regions your service is running in by two additional regions. In taking this approach, the service will still be able to respond to customer requests in the event of not only one regional outage but also any form of outage in a second region where the service is running. By adopting the n + 2 approach, there is a far better chance at meeting SLAs set with your customers.
Getting to this point will certainly present challenges but should also provide the opportunity to cut down (or even eliminate) toil within your organization. In the end, your customers will benefit from increased service resiliency, and your team will benefit from significant productivity gains.
Have a really great day!
Resources
- AWS Post-Event Summaries, AWS
- Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region, AWS
- danluu/post-mortems, GitHub
- “Identifying and Tracking Toil Using SRE Principles” by Eric Harvieux, 2020
- “Failure Recovery: When the Cure Is Worse Than the Disease” by Guo et al., 2013